
The Complete Guide On Text-To-Speech Software: Why Use It? Where To Get It Free? Plus TTS Support In The Top Authoring Tools
You’re familiar with computer-generated voices. Our phones now talk to us with voices that sound almost human, so much so that we can have simple conversations with them that sound natural. We are now using devices in our homes like Alexa, Cortana, and Google Home, which are doing the same—and we don't seem to mind so much that they're always listening. Even some of our kitchen appliances and our cars seem to have found a voice. And it's certainly easier for me to send an error-free text if I dictate the text to my phone with my voice rather than fumbling with the on-screen keyboard with my big thumbs!
Of course, each of those devices tends to use one voice only and, in most cases, has a limited vocabulary so it’s not difficult to optimize each one to sound its best.
We used to consider computer voices, especially text-to-speech (TTS) voices, useful mostly for those with vision impairments. In eLearning, when we use narration we usually record our own voices or we use expert voiceover artists. The latter make eLearning lessons sound professional and they are usually worth the cost—just like a documentary that is narrated by Morgan Freeman or by David Attenborough can be riveting, whereas the same script read by Gilbert Gottfried can be quite distracting. However, did you know that you can use professional narrators at a much lower cost by adopting TTS? Keep reading.
Why Use TTS Voices Even When You Intend To Use Human Narrators?
Scripts Change
Scripts are never set in stone at the start of a project. They usually are modified quite often before the project is considered complete. One of the reasons is that when we read a script, it may sound quite different in our heads than when we hear it spoken out loud. This alone leads to script changes as we note phrases that sound awkward or that are otherwise not clear.
There are other reasons, of course, such as realizing that there is a need to define acronyms the first time you use them, or determining that the narration is unnecessarily long. As native speakers, we read much faster than we speak, so what may seem reasonable when read may seem very long when heard.
Professional narrators are generally paid by the minute with a minimum number of minutes per session. Each time there is a script change and you must return to the narrator for an update, it will cost you. These costs can add up to a lot more than was originally budgeted. Even if you are recording your own voice, you will find yourself rerecording often. Each time, you will also need to ensure your environment is the same: quiet, same microphone levels, same distance from the microphone, etc.
Therefore, for these and other reasons, I will use TTS voices with the client’s full knowledge of the reasons why. After all the changes to the script are made and before the project is completed, I will let clients choose the professional narrator voice or voices, send the final scripts just once to the narrators, then replace the TTS audio with the narrator audio quickly. The narration will be consistent, correct and at the lowest cost.
Yet Some Clients…
Some of my clients actually like the TTS voices when they hear them, and prefer to continue using them in the final product as well. Certainly, using TTS leads to lower costs and easier updates in the future. In fact, while most of the TTS voices will not be mistaken for a true human, they do sound better than in the past, and much better than those built into our operating systems. Let’s look at those next.
TTS Voices Included In Windows And Macintosh
Modern operating systems include one or more voices that we can use in eLearning. However, they don’t usually sound that great. In Windows 10, for instance, you may find the selection of voices in Figure 1 when you go to the Control Panel > Ease of Access > Narrator > Voice.
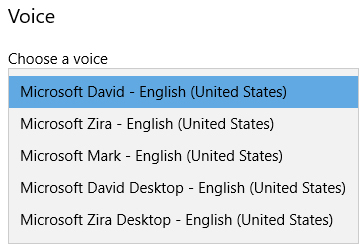
Figure 1. Windows 10 Narrator Voice Choices
You may also find that you can set options for the voice you choose, as seen in Figure 2.
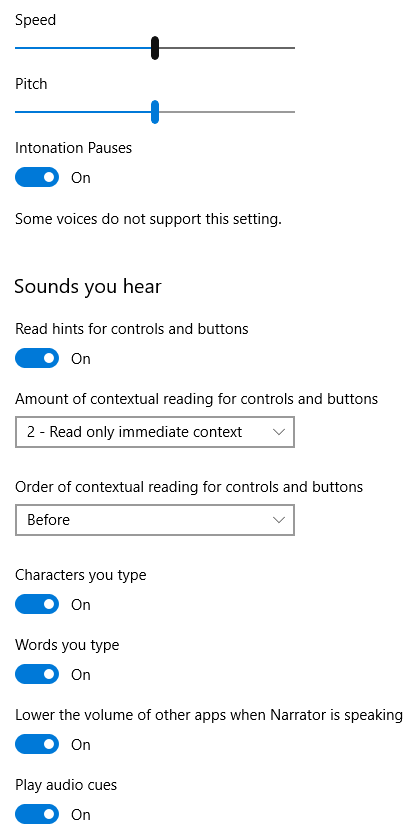
Figure 2. Windows 10 Narration Options
Similarly, on a Macintosh running OS X 10.6.8, you will find options at System Preferences > System > Universal Access > VoiceOver > Voiceover Utility. In later OS X versions, the location may differ slightly. Figure 3 shows the wide variety of system voices on a Mac, though I find only the Vicki voice to be marginally acceptable. Figure 4 shows how you can assign different voices and set parameters for each for different computer features.
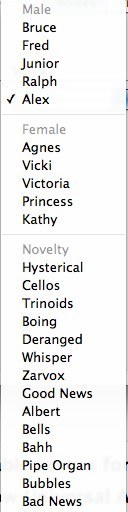
Figure 3. Mac OS Voice Choices
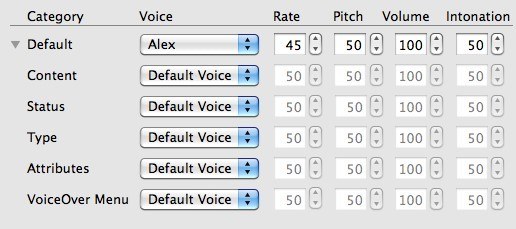
Figure 4. Mac OS X Narration Options
The 3 Top Authoring Tools that have the biggest market share are Adobe Captivate 2017, Articulate Storyline 360, and Trivantis Lectora 17.
The 3 tools differ in TTS offerings.
- Adobe Captivate has long included TTS features.
- Articulate introduced TTS in Storyline 360 past November.
- Trivantis Lectora does not yet include TTS. Keep reading, though, because there is a solution for those of you who use Lectora.
Adobe Captivate TTS
Voices Included
Captivate has included TTS voices since version 4 in January 2009. In Captivate 2017, seven voices licensed from NeoSpeech are included, as seen in Figure 5.
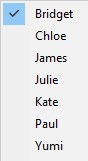
Figure 5. Captivate 2007 Included TTS Voices
- British English: Bridget
- French: Chloe
- Korean: Yumi
- US English: James, Julie, Kate, and Paul
Note that if you feed French text to Chloe, she will speak it correctly in French, though she sounds more like Canadian French rather than Parisian. Similarly, if you have Yumi speak text that is written in Korean, she will sound like a native Korean to a Korean speaker. On the other hand, if you have Chloe or Yumi speak English text, they will sound very much like a French person speaking English with a heavy French accent or a Korean person speaking English with a heavy Korean accent, respectively.
Generating The TTS Audio
There are a couple of ways to create TTS-generated narration in Captivate, and they are both easy and fast.
1. Add TTS to any or all slides in one place by choosing Audio > Speech Management. You can paste the scripts from elsewhere or type them directly. See Figure 6.
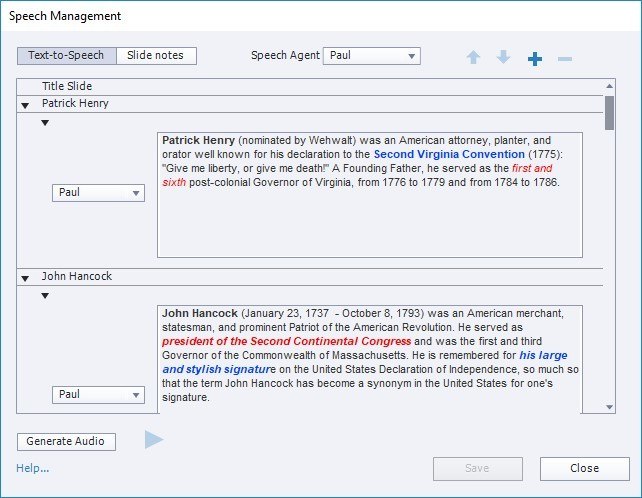
Figure 6. Speech Management in Captivate
2. For any slide, you can enter a script in its Slide Notes, then check the box to copy it into the text-to-speech location. (You can also check another box to turn the Slide Notes into closed captions.) See Figure 7.
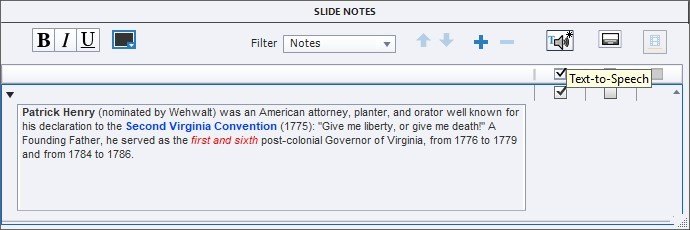
Figure 7. Slide Notes Option
Note in the above two figures that you can format the text using boldface, italics, underline, and colors. Using Captivate’s Export Captions to Word option, the formatting is retained so that if you wanted to hand the Word document later to a professional narrator, the formatting can indicate where to stress certain phrases or words. See Figure 8.

Figure 8. Word Export
Mix And Match Voices
An important feature among Captivate’s TTS abilities is that you can have as many scripts as you like in the order you wish, on any slide. This means that you can have a conversation occur between two or more people, such as the one you see in Figure 9. The result will be one audio track on Slide 1 that contains the conversation in the order shown. You can then edit the track using Captivate's built-in audio editor if you wish. For instance, while Captivate will add a natural pause between different parts of the conversation, you can change the length of the individual pauses if you wish.
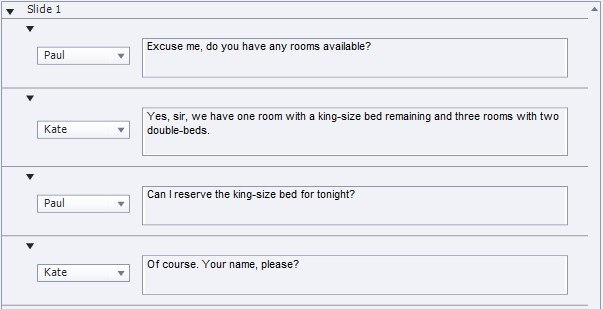
Figure 9. A Conversation
You can also use this option to use different voices when there is more than one language used within the same text. For example, see Figure 10.
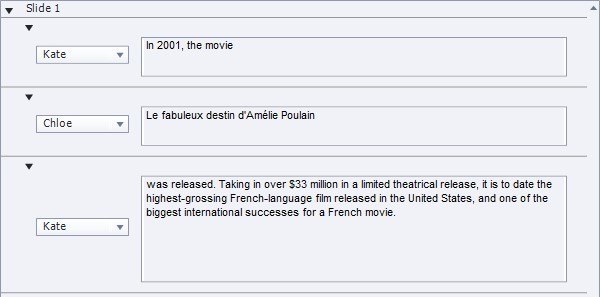
Figure 10. Mixing Languages in TTS
Using Optional VoiceText Meta Tags
In addition to formatting the text, you can also use VoiceText™ Meta Tags (VTML) to control the voice in many ways, summarized below. For more detail, download this guide.
1. Breaks
Set a break level.
<vtml_break = "0"/> read continuously
<vtml_break = "1"/> read with minor break
<vtml_break = "2"/> read with major break
<vtml_break = "3"/> sentence separation
2. Parts Of Speech
Indicate the part of speech for the next word.
<vtml_partofsp part = "unknown" | "noun" | "verb" | "modifier" |
"function" | "interjection">
text
</vtml_partofsp>
There are many words in English that are both a noun and a verb and, in each case, they are pronounced differently. For instance, read this paragraph out loud and you’ll note the differences in pronunciations.
We are going to record a record. We will refuse the refuse. We will progress until we achieve a lot of progress. For the party, we will produce a lot of produce. Do not contest the contest! If you rebel, you're a rebel. We will not subject you to such a boring subject. I will contrast the contrast feature of these different televisions.
Remarkably, NeoSpeech will pronounce each of the nouns and verbs in the sentence above correctly. However, there are many more examples in English of nouns and verbs that are written the same but are pronounced differently. If you ever find that a word isn’t being pronounced correctly due to NeoSpeech not understanding from the sentence structure the part of speech for that word, you can tell it which part of speech it is using this tag.
3. Pause
Pause for the milliseconds indicated.
<vtml_pause time="msec"/>
4. Phonetic Symbols
(see the PDF link above for details)
<vtml_phoneme
ph="string"
alphabet="ipa" | "x-cmu" | "x-pentax" | "x-sapi" | "x-sampa" |
"x-worldbet" | "x-pinyin">
text
</vtml_phoneme>
5. Pitch
Set the pitch for the text shown.
<vtml_pitch value="pitch">
text
</vtml_pitch>
6. Say As
(see the PDF for details)
Set the format for the text.
<vtml_sayas interpret-as="construct_type" format="string" detail="string">
text
</vtml_sayas>
7. Sub
Lets you define alternate text to read for a text passage.
<vtml_sub alias="string">
text
</vtml_sub>
8. Volume
Set the volume from 0 to 500%.
<vtml_volume value="volume">
text
</vtml_volume>
Important NeoSpeech Utilities
Besides allowing you to use VTML tags, the NeoSpeech folders that are installed as part of Captivate let you customize in advance how acronyms, or any industry terms you use, should be pronounced. You do this once only, and thereafter the word or phrase will always be pronounced correctly.
In Windows, the Program File folder Adobe Captivate Voices 2017 x64/VT/ is where the voice folders can be found. See Figure 11.
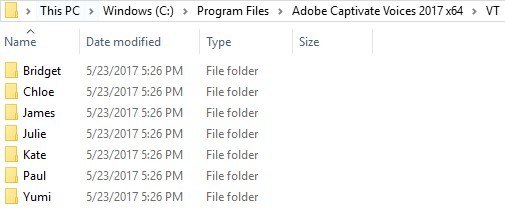
Figure 11. The Location of the NeoSpeech voice fold
Within each of the above folders is a subfolder called M16, which in turn contains three folders. One of those is the bin folder, which contains two executable files:
UserDicEng.exe lets you define exactly how words should be pronounced. See Figure 12.
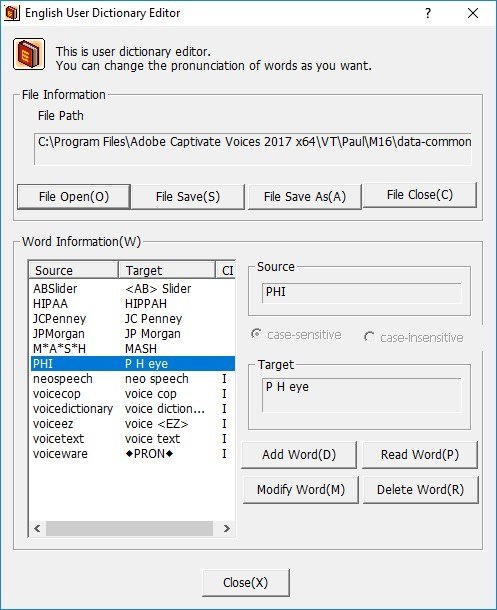
Figure 12. Editing the Voice Dictionary
You can add as many words as you like and in each case define the pronunciation using alphabetic characters, such as in the case of Figure 13, which indicates that ABSlider should be pronounced as AB Slider and not as abslider.
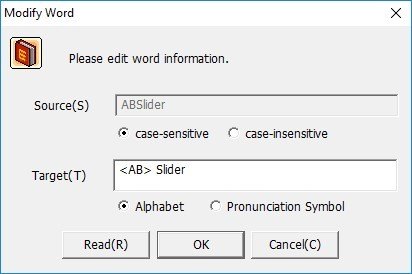
Figure 13. Adding or Modifying a Word
You can also use pronunciation symbols when alphabetic characters don’t suffice, such as in Figure 14.
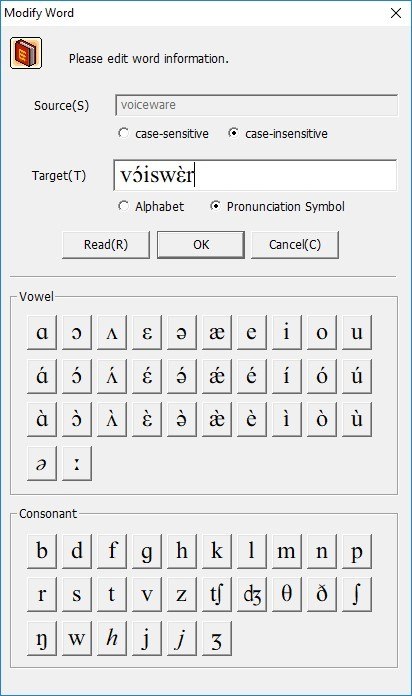
Figure 14. Using Pronunciation Symbols
VTEditor_ENG.exe: Lets you play back whole text passages in the voice you select. See Figure 15. While useful to test whether certain words will be pronounced incorrectly—after which you can take measures to fix that using the Dictionary Engine above—unfortunately, you cannot generate the audio files from this application (the Wave option is disabled.)
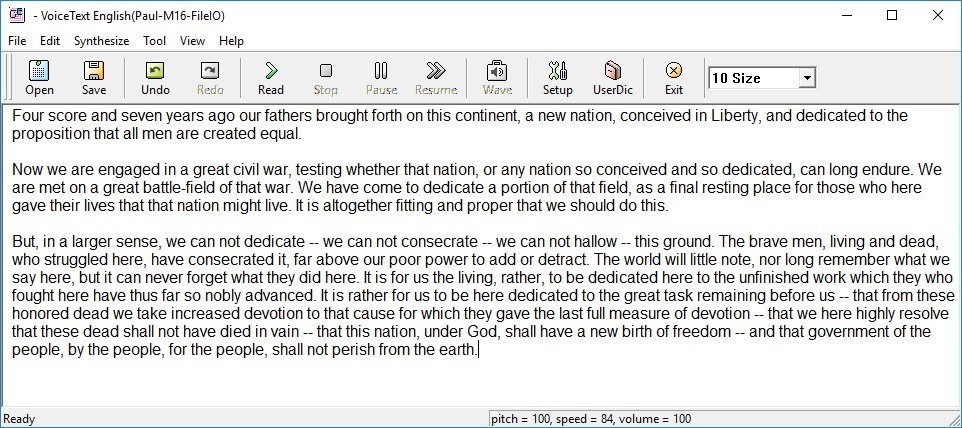
Figure 15. The VoiceText Application
In Captivate, the quickest way to swap out the TTS voices for your own voice files or for files sent to you by a professional narrator, is to open the Library Audio section, click each audio file there and click Import to replace the audio with that of the professional. This usually takes just a few minutes, even if you have many audio files.
Articulate Storyline 360 TTS
In November 2017, Articulate added TTS ability to Storyline 360. Storyline 3 does not include this feature at this time. However, you can open Storyline 360 files that contain text-to-speech audio in Storyline 3 without losing the audio, though you cannot create new text-to-speech audio narration or make any changes to the existing narration in Storyline 3.
Voices Included
Storyline uses the Amazon Polly text-to-speech engine, so currently you have access to the languages you see in Figure 16. You can always see the updated list of languages here.
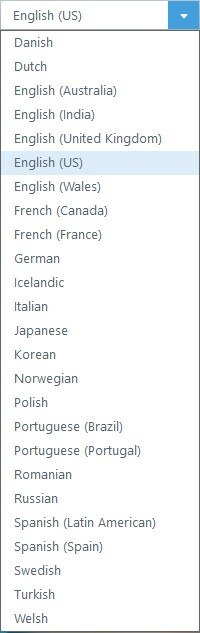
Figure 16. Storyline 360 Voices
Generating The TTS Audio
You can add TTS to a slide by using Insert > Audio > Text-to-Speech. See Figure 17. Once you have inserted the generated voice audio, do not use this option if you need to modify the script text or change the voice used. The dialog you see will come up empty each time. Instead, right-click the audio track that was generated by the TTS to return to its script.
You can also paste the text from the Slide Notes for the current slide here by clicking a button. There are no options for formatting the text.
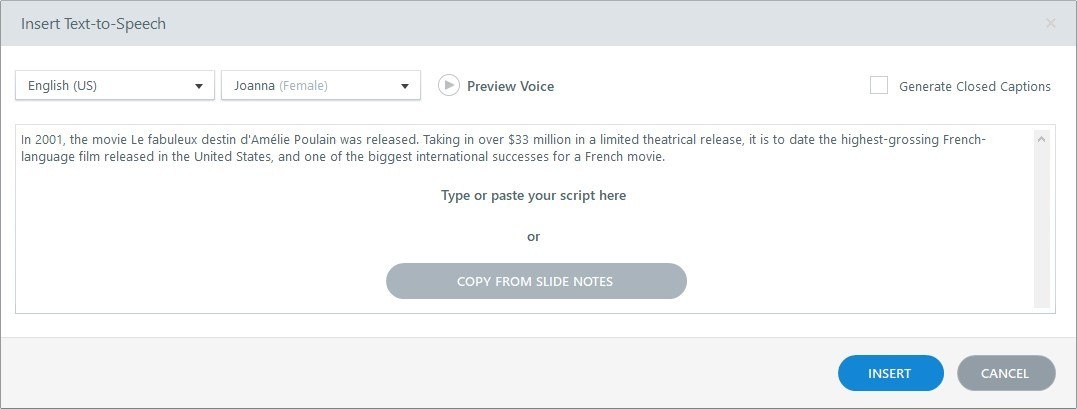
Figure 17. Storyline's Text-to-Speech Option
Creating Conversations
You cannot create a conversation between voices directly in the TTS window. However, as Storyline does allow for multiple audio tracks, you could generate three separate audio tracks and concatenate them on the timeline, such as you see in Figure 18. This has the advantage of letting you time the two sides of the conversation with more space between each part if you wish, so as to insert other screen events in between.
Alternatively, you can export the three tracks and then combine them into one track in an external editor or in Storyline’s own audio editor. This can be time-consuming, especially if you have multiple slides where you must have conversations between doctor and patient, attorney and client, or any other situation.
Figure 18. Concatenating Audio
This being a recent addition to Storyline 360, it is understandable that there are other limitations to its text-to-speech abilities when compared to the long-present TTS in Adobe Captivate:
- You cannot enter all the narration for every slide in one place. You must create or paste the scripts into each slide, then generate the audio for that slide.
- There is no way to preset the pronunciations for words in a voice dictionary. If a word is being pronounced incorrectly, you must modify the script to make it sound the way it should. For instance, in the case of my last name (Ganci), I would need to write it out phonetically (or have an Italian voice say it) to make it sound correct each time I use it rather than just defining its pronunciation once. After trying GHAN-chee, GAN-chee, GAHN-chee, and several other combinations, I gave up on having the US voice pronounce my name correctly because each time it insisted on pronouncing the A in my name as the A in CAN rather than the A in FATHER. However, when I wrote KHAN-chee, it pronounced the A correctly, though—of course—the K is wrong.
- While Amazon’s Polly voices do allow for Speech Synthesis Markup Language (SSML) tagging, that is not currently possible in Storyline. Therefore, you cannot change the pitch, volume, or other aspects of your text-to-speech. You will need to edit the generated audio later to introduce these kinds of changes.
- In the Storyline TTS dialog, you can preview each voice, in which case you’ll hear the voice introduce itself by name and then say it will read any text. However, you can’t preview the voice reading your script. You must insert it into your timeline before you can hear the voice reading the script.
The above limitations aside, I’m happy to see Storyline 360 now includes text-to-speech features. One feature in which it beats Captivate is in the number of voices available through Amazon Polly. See below for more.
Other Ways To Obtain TTS Audio
Most authoring tools, like Trivantis Lectora, do not include TTS voices. In addition, you may want to have other choices besides those that you find in Adobe Captivate and in Articulate Storyline. You’ll be happy to know that there are other options online for creating and downloading TTS narration, though be aware that this process is more laborious, as you'll need to create the audio files online individually, download them, then insert them into your lesson file.
1. Amazon Polly – Free And Paid
Remember that Articulate Storyline 360 uses the Amazon Polly voices. Figure 16 shows the full list of voices available. However, if you do not use Storyline 360, you can still use these voices.
You can generate up to 5 million characters per month for speech at no cost. That’s 1,640 pages of single-spaced text/90 hours of narration! It’s unlikely that you’ll need even that much. However, if you do, after that it costs $4.00 a month per 1 million characters.
2. From Text To Speech - Free
This site includes the following voices:
US English: Alice, Daisy, George, Jenna, and John
British English: Emma and Harry
French: Gabriel and Jade
Spanish: Isabella and Mateo
German: Michael and Nadine
Italian: Alessandra and Giovanni
Portuguese: Rodrigo
Russian: Valentin
In each case, you can choose between Slow, Medium, Fast, and Very Fast speeds.
Type or paste your text in the box provided and click the Create Audio File button. When done, you can download the resulting MP3 file and insert it into your learning.
3. Natural Readers – Free And Paid
Free And Paid For Personal Use
The free version of Natural Readers is for personal use only, and includes up to 20 minutes per day for Premium Voices and no limit to the Free Voices used. You can paste or type your scripts, or upload PDF, DocX, RTF, TXT, and ePub documents. In each case, you can choose between speeds ranging from -4 to 9 and you can download the resulting MP3 files.
Free includes 20 minutes per day. Voices include US English, British English, French (France and Canada), Spanish (Spain, Mexico, Castilian, and US), German, Italian, Portuguese (Portugal and Brazil), Swedish, and Dutch.
For $60 per year, there is no limit to the time, though you are limited to 1 million characters a year, and you have access to 57 Premium Voices. For $72 per year, you can convert up to 5 million characters each year.
Commercial Use
To use TTS audio created on Natural Readers for eLearning, you can try the Commercial version free for a limited time, after which you can license a single user for $588 a year, four users for $948 a year, or you can go month to month for $99 a month for a single user.
The commercial version includes access to 47 high-quality voices from 24 different languages: English (US, Australian, British, Indian, and Welsh), French (France, Canada), Spanish (Castilian, American), Portuguese (Portugal, Brazil), Welsh, Danish, Dutch, German, Icelandic, Italian, Japanese, Polish, Romanian, Russian, Swedish, Turkish, and Norwegian. These are different voices from those included in the free version. It also includes a Pronunciation Editor, an Audio Editor, and SSML tags.
Natural Readers Software
This site also includes software you can download for Windows and for Macintosh for personal use only. There is a free version and there are paid versions that range from $70 to $200, a one-time fee. See what’s included here.
4. IBM Watson Services – Free And Paid
As part of its Watson services, IBM provides text-to-speech. It builds on the IBM Cloud, which includes many other services, and you can download the resulting MP3 files. Its voices include several languages. Under the Lite plan, which has no cost, the first 100 minutes per month are free. The Standard plan is tiered, ranging from $0.01 to $0.02 US per minute. The Premium plan offers high-end services and you will need to contact IBM for pricing here.
5. iSpeech – Paid
iSpeech offers a number of languages: English (US, UK, Australian, Canada), Mandarin, Hong Kong Cantonese, Japanese, Korean, Hungarian, Portuguese (Portugal, Brazil), Spanish, Catalan, Czech, Danish, Finnish, French (France, Canada), Norwegian, Dutch, Polish, Italian, Turkish, Greek, German, Russian, Arabic, and Swedish. This is one of the most costly services but it may be worth it, if you agree that their voices are worth the price. Prices range from $500 for 10,000 words (5 cents per word) to $2,500 for 100,000 words (2 cents per word).
6. NeoSpeech – Paid
NeoSpeech, the engine used by Adobe Captivate that includes unlimited use of seven voices in US and UK English, French, and Korean among others, also offers an online service to convert text to speech separately for you to use where you wish. Pricing is also higher than most: $25 for 400 words (6 cents per word), $50 for 1,000 words (5 cents per word), and $100 for 2,400 words (4 cents per word). There are more than 40 languages available, including English (US and UK), Spanish, French (France and Canada), Portuguese, Italian, German, Korean, Japanese, Mandarin, Cantonese, Taiwanese, and Thai.
Convinced?
Are you convinced that TTS can be useful to you? Using the built-in TTS options within Captivate and Storyline may suffice. If not, you can also create TTS voices online, many at no cost. Unless you plan on using high-quality TTS voices for the final version of your eLearning, you probably can do with lesser quality voices for your eLearning drafts until the scripts are finalized, after which you can swap out the TTS voices in favor of the professional narrator or your own voice files.
